Feature Engineering 特征工程 1. Baseline Model
本文共 2402 字,大约阅读时间需要 8 分钟。
文章目录
下一篇:
1. 读取数据
预测任务:用户是否会下载APP,当其点击广告以后
数据集:ks-projects-201801.csv- 读取数据,指定两个特征
'deadline','launched',parse_dates解析为时间
ks = pd.read_csv('ks-projects-201801.csv',parse_dates=['deadline','launched']) 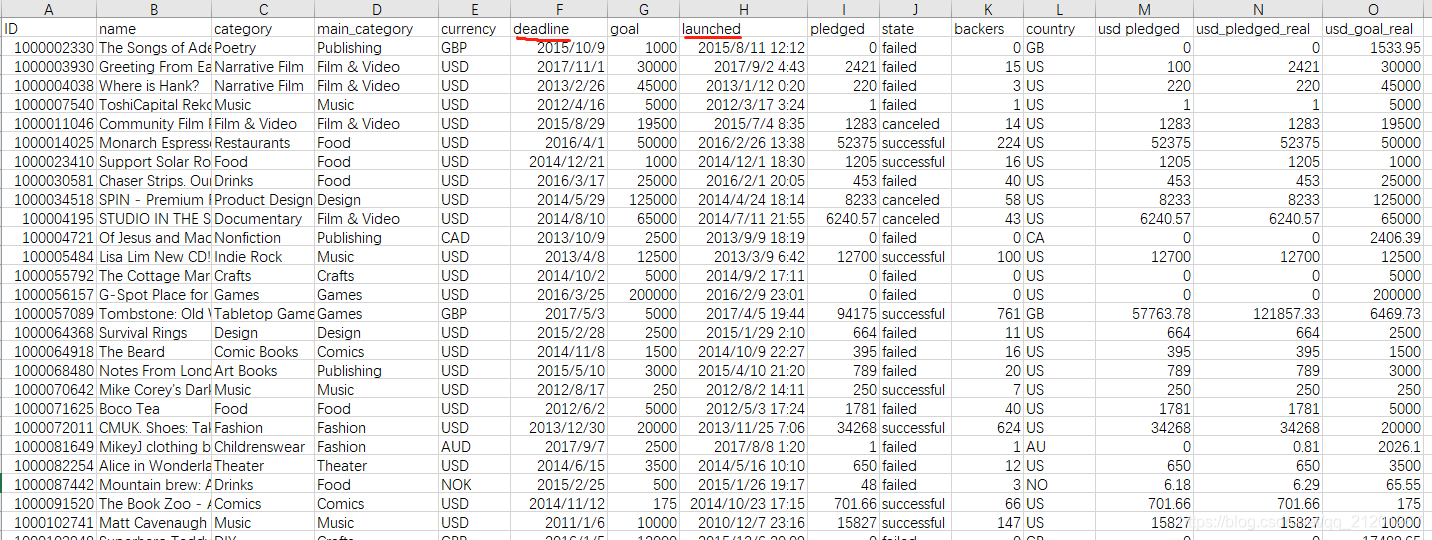
state作为结果label 可以使用类别category,货币currency,资金目标funding goal,国家country以及启动时间launched等特征 2. 处理label
- 准备标签列,看看有哪些值,转换成可用的数字格式
pd.unique(ks.state)
有6种数值
array(['failed', 'canceled', 'successful', 'live', 'undefined', 'suspended'], dtype=object)
每种多少个?按state分组,每组中ID行数有多少
ks.groupby('state')['ID'].count() statecanceled 38779failed 197719live 2799successful 133956suspended 1846undefined 3562Name: ID, dtype: int64
- 简单处理下标签列,正在进行的项目
live丢弃,successful的标记为1,其余的为0
ks = ks.query('state != "live"') # live行不要ks = ks.assign(outcome=(ks['state']=='successful').astype(int))# label 转成1,0,int型 3. 添加特征
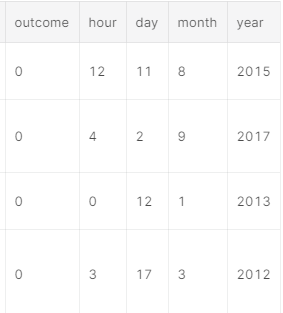
- 把
launched时间拆分成,年月日小时,作为新的特征
ks = ks.assign(hour=ks.launched.dt.hour, day=ks.launched.dt.day, month=ks.launched.dt.month, year=ks.launched.dt.year)ks.head()
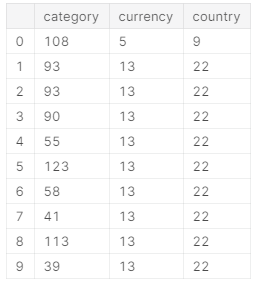
- 转换文字特征
category, currency, country为数字
from sklearn.preprocessing import LabelEncodercat_features = ['category','currency','country']encoder = LabelEncoder()encoded = ks[cat_features].apply(encoder.fit_transform)encoded.head(10)
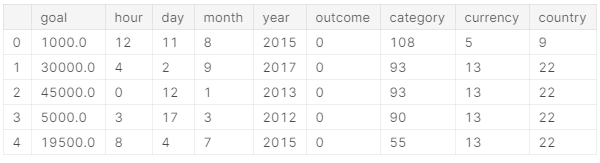
- 将选择使用的特征合并在一个数据里
X = ks[['goal', 'hour', 'day', 'month', 'year', 'outcome']].join(encoded)X.head()
4. 数据集切片
- 数据切片,按比例分成训练集、验证集、测试集(0.8,0.1,0.1)
- 更高级的简单做法
sklearn.model_selection.StratifiedShuffleSplit
valid_ratio = 0.1valid_size = int(len(X)*valid_ratio)train = X[ : -2*valid_size]valid = X[-2*valid_size : -valid_size]test = X[-valid_size : ]
需要关注下,label 在每个数据集中的占比是否接近
for each in [train, valid, test]: print("Outcome fraction = {:.4f}".format(each.outcome.mean())) Outcome fraction = 0.3570Outcome fraction = 0.3539Outcome fraction = 0.3542
5. 训练
- 使用LightGBM模型进行训练
feature_cols = train.columns.drop('outcome')dtrain = lgb.Dataset(train[feature_cols], label=train['outcome'])dvalid = lgb.Dataset(valid[feature_cols], label=valid['outcome'])param = { 'num_leaves': 64, 'objective': 'binary'}param['metric'] = 'auc'num_round = 1000bst = lgb.train(param, dtrain, num_round, valid_sets=[dvalid], early_stopping_rounds=10, verbose_eval=False) 6. 预测
- 对测试集进行预测
from sklearn import metricsypred = bst.predict(test[feature_cols])score = metrics.roc_auc_score(test['outcome'], ypred)print(f"Test AUC score: {score}") 下一篇:
转载地址:http://nuhtf.baihongyu.com/
你可能感兴趣的文章
Python从零开始——解释器
查看>>
Python从零开始——基本数据类型
查看>>
Python从零开始——条件控制语句
查看>>
Python从零开始——集合Set
查看>>
Python从零开始——迭代器与生成器
查看>>
Python从零开始——循环语句
查看>>
Odoo学习笔记一:odoo初探
查看>>
Odoo 启动选项总结
查看>>
Odoo配置文件
查看>>
odoo10学习笔记十一:视图综述
查看>>
commons-dbutils【不推荐】
查看>>
SOCAT端口转发
查看>>
docker快速搭建HTTP代理
查看>>
jpa的entry审查Auditing
查看>>
mongdb查询笔记
查看>>
facebook区块链libra测试网体验
查看>>
前端学习 -- Css -- 属性选择器
查看>>
前端学习 -- Css -- 字体
查看>>
前端学习 -- 颜色
查看>>
前端学习 -- Css -- 盒子模式
查看>>